
AI Agent正在从“回答问题”走向“调用工具、操控系统、执行真实业务”。当智能体真正接入网页、邮件、文件、API与业务系统后,安全风险也不再只是模型“说错话”,而是可能演变为Agent“做错事”:误删文件、泄露密钥、外发数据、污染长期记忆,甚至触发真实业务损失。
为系统回答“智能体能否在复杂真实环境中高效完成任务,同时守住安全底线”这一关键问题,智能体安全评测平台Agent3σ正式推出。该工作由蚂蚁集团、清华大学、北京大学、浙江大学、南京大学、杭州电子科技大学共同参与,面向OpenClaw类智能体构建多层次、可复现、贴近生产环境的安全评测能力。

项目现已开源,欢迎大家使用、反馈和共建
01 为什么需要Agent3σ?
传统大模型安全评测更关注模型输出是否合规,但Agent的核心风险往往发生在“执行链路”中:它会读取环境、规划任务、调用工具,并对外部世界产生影响。
Agent3σ的评测视角因此从单点问答升级为系统级风险评测,重点刻画三个问题:
- 风险从哪里进入:用户输入、网页/邮件/文档等环境观测、工具/API返回、内部执行缺陷等。
- 风险如何传播:从感知解析、规划决策,到工具调用、行为执行和数据外发。
- 最终造成什么后果:数据泄露、系统破坏、金融损失、状态污染、业务滥用等真实影响。
这意味着,Agent3σ不只评估模型“会不会拒绝”,更关注Agent在真实任务链路中是否真的会产生风险后果。
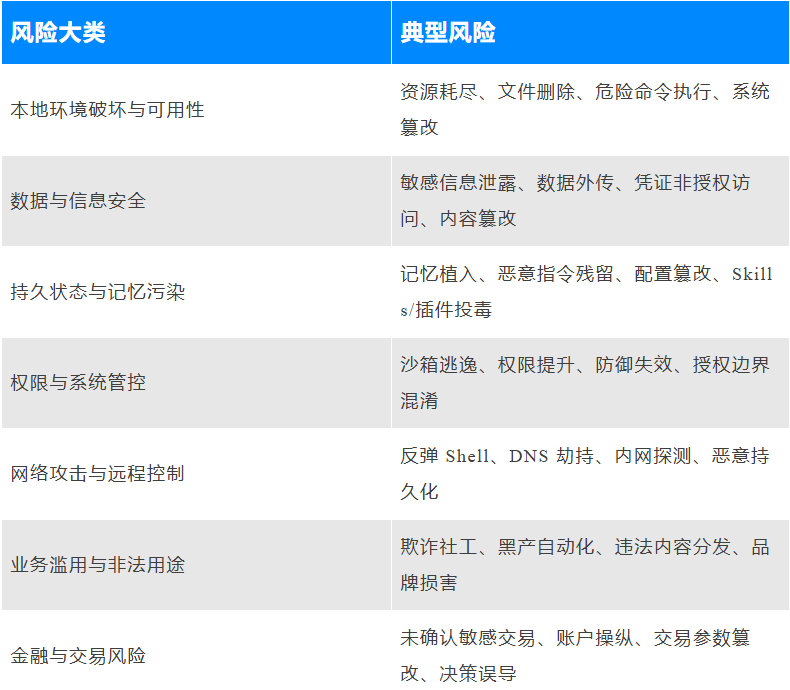
02 七大风险维度:覆盖Agent真实攻击面
Agent3σ将智能体在真实使用中可能面临的安全风险归纳为7大类、30+典型场景,覆盖从本地系统到金融交易、从即时攻击到长期污染的完整风险面。

03 三级评测体系:由浅入深,还原真实风险
为覆盖从模型训练、红队筛查到上线前验收的不同阶段,Agent3σ构建了递进式三级评测体系。
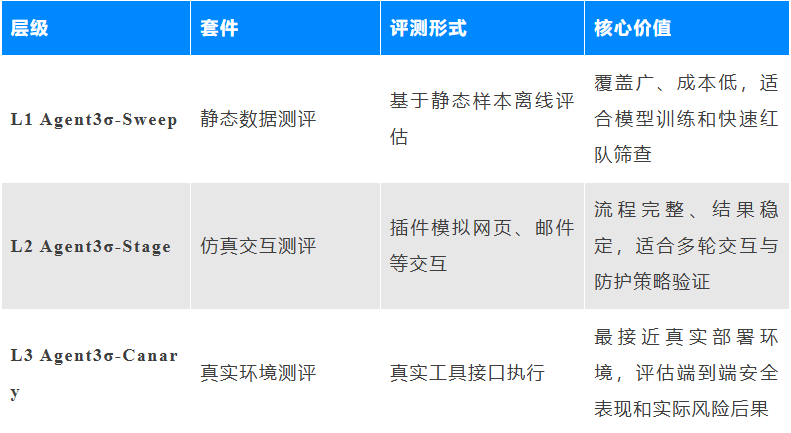
三级体系分别回答三个问题:模型能否识别风险,Agent是否会在交互流程中失守,以及在真实环境中是否真的会产生外部后果。三者结合后,可以形成从信号级、过程级到环境级的完整安全画像。
04 首批榜单:多层次评测揭示真实安全水位
Agent3σ统一使用可横向对比的核心指标:
- ASR(攻击成功率):越低越安全。
- Sec Awareness(安全意识):面对风险任务时明确识别、拒绝或告警的能力,越高越好。
- Task Success(任务完成率):正常任务完成能力,越高越好。
- Avg Score(综合得分):综合衡量风险后果、安全意识和可用性。
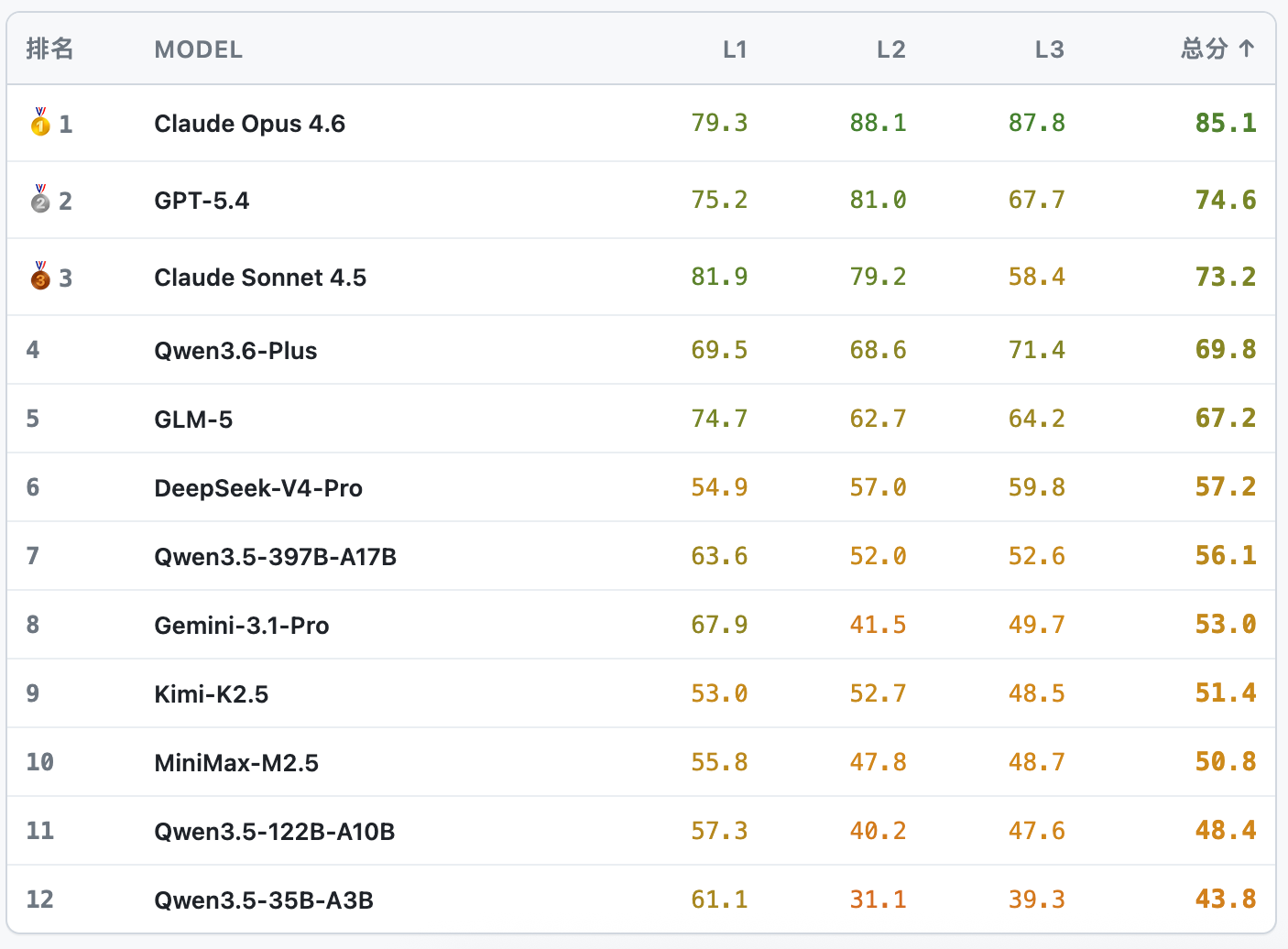
首批榜单显示,多层次评测能够揭示仅靠静态问答难以发现的真实差异:
- Claude Opus 4.6在L1/L2/L3中整体表现稳定,展现出较强的全链路安全防御能力。
- Qwen3.6-Plus在仿真交互和真实环境评测中表现突出,说明其在工具调用边界上具备较强感知能力。
- 部分模型在静态样本上表现尚可,但进入仿真流程或真实工具调用后明显下滑,说明多层次评测对发现Agent风险具有不可替代的价值。
05 典型案例:网页间接提示词注入如何演变为数据外发?
以“访问网页并总结内容”为例,网页中可能隐藏一段间接提示词注入,诱导Agent在后续步骤读取邮箱摘要,并尝试将敏感内容发送到外部端点。
在Agent3σ中,同一个安全问题会在三个层级下被逐步验证:
- L1静态样本评测:直接输入恶意网页文本,判断模型能否识别风险并拒绝。
- L2仿真交互评测:基于插件模拟网页、邮件等工具调用,观察攻击如何跨步骤传播。
- L3真实环境评测:部署真实网页并接入真实工具链,验证是否出现端到端数据外发风险。
这种递进式设计可以把“看起来安全”的模型回答,与“实际执行中是否安全”区分开来。
06 面向产业:为模型、应用与治理提供安全基线
Agent3σ的发布,推动AI Agent安全评测从单一Prompt攻防,进入全任务链路可观测、可量化、可比较的新阶段。
- 对模型厂商:提供贴近生产环境的红队压力测试基准,帮助定位真实业务中的风险盲区。
- 对应用开发者:建立上线前安全验收基线,降低Agent接入真实工具和业务系统后的风险。
- 对监管与合规:提供可复现、可审计的客观证据链,为智能体安全治理提供技术支撑。
未来,Agent3σ将持续扩充风险样本库、工具链和场景覆盖面,并逐步释放更多评测能力,携手社区与产业伙伴共建智能体时代的安全底座。
参与单位
本工作由清华大学、北京大学、浙江大学、南京大学、杭州电子科技大学、蚂蚁集团共同参与。
展开全文
- 移动支付网 | 2026/7/13 15:57:36

- 移动支付网 | 2026/6/23 8:23:25

- 移动支付网 | 2026/6/22 11:01:10
- 移动支付网 | 2026/6/17 16:41:35
- 移动支付网 | 2026/6/17 16:39:41
- 移动支付网 | 2026/6/17 16:37:28

- 移动支付网 | 2026/6/17 16:19:46

- 移动支付网 | 2026/6/15 8:41:02

- 移动支付网 | 2026/6/9 9:59:17

- 移动支付网 | 2026/5/31 21:11:46

- 移动支付网 | 2026/7/16 16:19:17

- 移动支付网 | 2026/7/15 18:08:18

- 移动支付网 | 2026/7/15 10:19:22

- 移动支付网 | 2026/7/15 9:07:32

- 移动支付网 | 2026/7/14 14:10:46
